In this post, we will learn how to delete duplicate records in SQL Server using CTE.
In the earlier version of SQL Server, if you need to delete duplicate records you had to the following steps
Let's first create a table
Now let's populate the table with duplicates records
In the earlier version of SQL Server, if you need to delete duplicate records you had to the following steps
- Store the distinct of duplicate records in some temp tables
- Delete the duplicate records from the main table
- Move the temp table data to main table
NOTE: CTE was introduced in SQL Server 2005, so the solution would work on SQL Server 2005 onward
Let's first create a table
CREATE TABLE tblduplicate( id INT, VALUE VARCHAR(10) )
Now let's populate the table with duplicates records
insert into tblduplicate select 1, 'value 1' union all select 1, 'value 1' union all select 1, 'value 2' union all select 2, 'value 2' union all select 2, 'value 2' union all select 3, 'value 3'
Now let's check the data in the table
select * from tblduplicateOUTPUT

Now lets write script to delete duplicates records from the table using CTE. In the solution first we would generate a sequential no. for duplicate records using Row_Number.
Suggested article to understand Row_Number in detail: Row_Number in SQL Server
Once row number is generated we would delete all the records where row number is greater than 1 as there are duplicate records.
;with cte AS ( SELECT id, VALUE , Row_number() OVER (PARTITION BY id, VALUE ORDER BY id) AS rowno FROM tblduplicate ) DELETE cte WHERE rowno > 1Now let's again check the data in the table
select * from tblduplicateOUTPUT
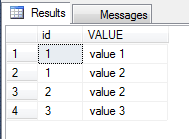
Check the output. Duplicate records are deleted from the table

